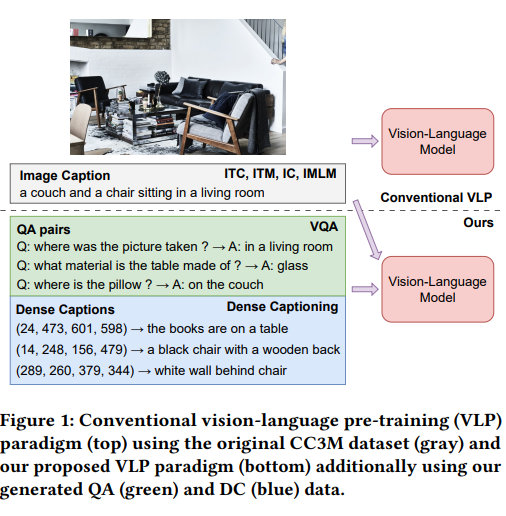
논문 요약
"In Defense of Grid Features for Visual Question Answering" 논문은 Visual Question Answering (VQA)에서 그리드 특징의 사용에 대한 깊은 분석과 실험을 제시합니다. 주요 내용을 요약하면 다음과 같습니다:
- 배경과 동기: 이 연구는 VQA 작업에서 특히 인기 있는 bounding box 또는 region 기반 시각적 특징에 대해 논의합니다. 이러한 특징들은 더 나은 위치 지정과 같은 이점 때문에 선호됩니다. 하지만, 이 논문은 그리드 기반 convolutional 특징으로 다시 돌아가 이들이 효과적이고, 디자인이 단순하며, 훨씬 빠를 수 있다고 주장합니다.
- 실험 설정 및 발견사항:
- 연구에서는 다양한 모델, 데이터셋, 디자인 파라미터를 고려하여 그리드와 region 특징을 VQA 작업에서 비교하는 실험을 사용합니다.
- 이 논문은 그리드 특징이 region 특징과 유사하게 pre-trained되고 최적화될 때 VQA 작업에서 비슷하거나 더 나은 정확도를 달성할 수 있다고 보고합니다.
- 특히 그리드 특징은 시간이 많이 걸리는 region 선택 및 계산 단계를 없애므로 region 특징에 비해 주요한 속도 개선을 제공합니다.
- 그리드 특징의 장점:
- 모델 디자인의 단순성: 그리드 특징은 모델 디자인과 학습 과정을 더 간단하게 만듭니다.
- End-to-End 학습: 이 논문은 그리드 특징을 사용하여, pre-training에서 region 주석 없이 픽셀에서 직접 답변으로 VQA 모델을 end-to-end로 학습하는 것이 가능함을 보여줍니다.
- 유연성: 그리드 특징은 Pyramid Pooling Module과 같은 네트워크 디자인 가능성을 더욱 유연하게 만들어 VQA 성능을 더욱 향상시킬 수 있습니다.
- 일반화 및 응용:
- 이 발견은 다양한 VQA 모델, 데이터셋에 잘 일반화되며, 이미지 캡셔닝과 같은 다른 작업으로 확장됩니다.
- 그리드 특징은 region 특징과 경쟁력 있는 정확도를 유지하면서 처리 속도에서 상당한 개선을 제공하여 실용적인 응용에 매우 적합합니다.
- 결론 및 함의:
- 논문은 시각적 특징의 형식(그리드 대 region)이 정확도에 큰 영향을 미치지 않는다고 결론짓습니다. 대신, 특징의 의미 있는 내용이 더 중요합니다.
- 연구자들은 그리드 특징을 VQA에서 유망한 방향으로 제안하며, 이들의 단순성, 효율성 및 효과성으로 인해 시각 및 언어 연구에 대한 새로운 길을 열었습니다.
- 실용적 응용: 이 연구의 결과는 계산 자원 또는 응답 시간이 중요한 요소인 상황에서 VQA 시스템의 실용적인 응용에 중요한 함의를 가집니다.
이 논문은 Visual Question Answering 분야에 주목할 만한 기여를 하며, AI 및 컴퓨터 비전 분야에서 연구와 응용의 새로운 방향을 제시합니다.
주요 특징
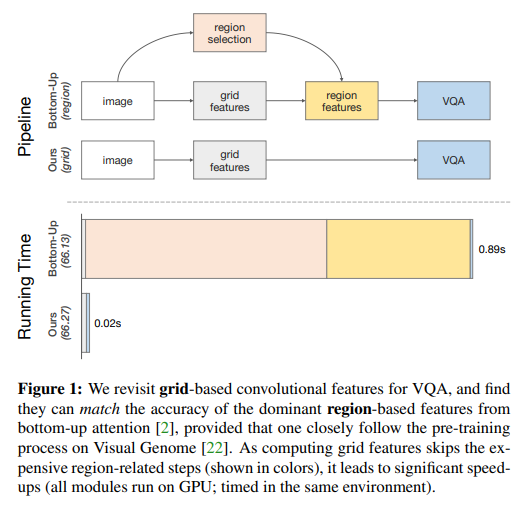
논문 "In Defense of Grid Features for Visual Question Answering"의 Figure 1은 VQA 작업에서 그리드 특징과 region 특징의 처리 과정과 성능을 비교하는 것을 시각적으로 보여줍니다. 이 그림의 주요 내용은 다음과 같습니다:
- 비교 구조:
- 그래프는 두 가지 접근 방식, 즉 '그리드 기반' (Ours)과 'region 기반' (Bottom-Up) 접근 방식의 처리 파이프라인을 비교합니다.
- 각 방식은 이미지를 입력으로 받아 VQA 처리를 거쳐 결과를 출력합니다.
- 그리드 특징의 파이프라인 (Ours):
- 그리드 특징을 추출하는 과정은 간결하고, 이를 바로 VQA 모델에 입력합니다.
- 처리 시간은 0.02초로 표시되어 region 기반 접근 방식에 비해 훨씬 빠르다는 것을 강조합니다.
- Region 특징의 파이프라인 (Bottom-Up):
- Region 선택 단계를 포함하여 그리드 특징보다 더 복잡한 여러 단계를 거칩니다.
- 그 결과, 처리 시간이 0.89초로 그리드 특징 방식보다 훨씬 길게 나타납니다.
- 성능 비교:
- 두 방식 모두 유사한 성능 (Ours: 66.27, Bottom-Up: 66.13)을 보여주지만, 그리드 특징이 훨씬 빠른 처리 속도를 제공한다는 점을 강조합니다.
이 그림은 VQA 작업에서 그리드 특징이 region 특징과 비교하여 유사한 성능을 제공하면서도 훨씬 빠른 처리 속도를 가진다는 논문의 주요 주장을 시각적으로 보여주는 중요한 요소입니다.
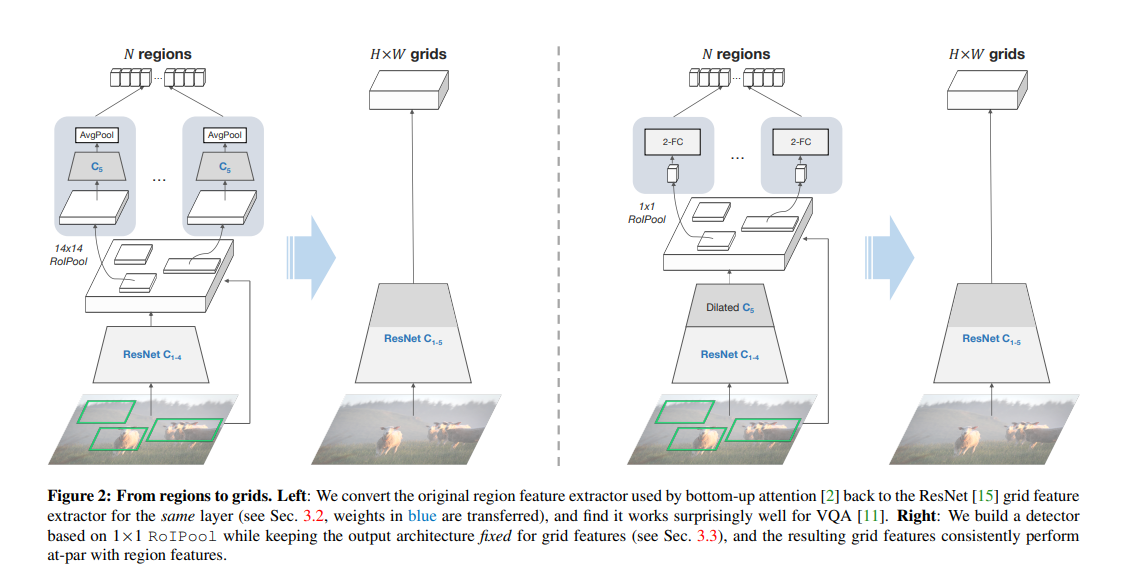
Figure 2: 영역에서 그리드로.
왼쪽: 우리는 bottom-up attention [2]에서 사용한 원래의 영역 특징 추출기를 ResNet [15] 그리드 특징 추출기로 변환합니다 (Sec. 3.2 참조, 파란색 가중치가 전달됩니다). 그리고 이것이 VQA [11]에 놀랍게 잘 작동한다는 것을 발견합니다.
오른쪽: 우리는 1×1 RoIPool을 기반으로 한 탐지기를 구축하면서 그리드 특징에 대한 출력 아키텍처를 고정시키고, 그 결과 그리드 특징이 일관되게 영역 특징과 비슷한 성능을 내는 것을 확인합니다.
3.1. Bottom-Up Attention with Regions
이 섹션에서는 Faster R-CNN 검출 모델을 사용하는 bottom-up attention 방법을 설명합니다. 이 모델은 Visual Genome 데이터셋을 사용하여 수천 개의 객체 카테고리와 수백 개의 속성을 bounding box(지역) 주석과 함께 학습합니다. VQA와 같은 작업에 bottom-up attention 특징을 얻기 위해서는 두 가지 지역 관련 단계가 필요합니다:
- Region Selection: Faster R-CNN은 두 단계 검출기로, 지역 선택은 파이프라인에서 두 번 발생합니다. 첫 번째는 지역 제안 네트워크를 통해 진행되며, 후보 '앵커'로서의 관심 영역을 선택합니다. 두 번째 선택은 후처리 단계에서 클래스별로 상위 N개의 상자를 집계합니다. 두 단계 모두 non-maximal suppression(NMS)을 사용합니다.
- Region Feature Computation: 첫 번째 단계에서 얻은 지역(수천 개에 이르는)에서 RoIPool 작업을 사용하여 초기 지역 레벨 특징을 추출합니다. 추가 네트워크 레이어는 지역의 출력 표현을 별도로 계산합니다. 마지막으로 두 라운드의 선택을 통과한 지역 특징들은 이미지를 표현하는 bottom-up 특징으로 쌓입니다【53†source】.
3.2. Grid Features from the Same Layer
이 섹션은 지역 특징을 그리드 특징으로 변환하는 가장 간단한 방법을 탐구합니다. 원래 bottom-up attention에 사용된 특정 Faster R-CNN 아키텍처를 살펴봅니다. Faster R-CNN은 C4 모델의 변형으로, 속성 분류를 위한 추가 분기가 있습니다. 입력 이미지를 주어진 후, ResNet의 하위 블록을 사용하여 C4까지 특징 맵을 계산합니다. 이 특징 맵은 모든 지역에서 공유됩니다. 그런 다음 지역별 특징 계산이 C5 블록을 적용하여 수행됩니다. C5의 출력은 각 지역에 대한 최종 벡터로 AvgPool됩니다. 이 과정은 그리드 특징으로 간단하게 전환될 수 있으며, 실험 결과 C5 출력을 직접 사용하는 것만으로도 놀라운 성능을 보여줍니다【54†source】.
3.3. 1×1 RoIPool for Improved Grid Features
이 섹션에서는 1×1 RoIPool을 사용하는 아이디어를 제시합니다. 이는 각 지역을 2D의 다양한 객체 부분을 특성화하는 데 유용한 두 개의 추가 공간 차원(높이와 너비) 대신 단일 벡터로 표현하는 것을 의미합니다. 이러한 변환은 객체 검출 성능에 부정적인 영향을 미칠 수 있지만, 각 그리드 특징 맵의 벡터가 공간적 영역의 모든 정보를 담아야 하므로 더 강력한 그리드 특징을 만들 수 있습니다. 원래 모델에서 1×1 RoIPool을 직접 적용하는 것은 문제가 될 수 있으나, 객체 검출에서의 최신 발전을 따라 전체 ResNet을 C5까지의 백본으로 사용하고, 지역 레벨 계산을 위해 상단에 두 개의 1024D 완전 연결(FC) 레이어를 배치합니다. 낮은 해상도의 효과를 줄이기 위해 C5에서 풀링된 특징을 학습할 때, 스트라이드-2 레이어는 스트라이드-1 레이어로 대체되고 나머지 레이어는 팽창 비율 2로 확장됩니다. 그리드 특징 추출을 위해 이러한 팽창을 제거하고 일반 ResNet으로 다시 전환합니다【55†source】.
'논문 분석 > Image captioning' 카테고리의 다른 글
| Enhancing Vision-Language Pre-Training withJointly Learned Questioner and Dense Captioner (0) | 2023.11.15 |
|---|