Model 영역
- Video captioning의 주요 사용 모델 및 구조
Application 영역
- 각 Application 영역에서 Video captioning의 연구 사례 & 활용 가능성
- Surveillance system에 적용된 Video captioning 연구 사례 & 활용 가능성
Model 영역
- Video captioning의 주요 사용 모델 및 구조
Video Understanding 분야에는 다양한 Task를 포함하고 있다.
입력 = Video 출력 = Text
비디오 분류(Video Classification)
비디오 캡셔닝(Video Captioning)
비디오 질의응답(Video Question & Answering on Video)
입력 = Video 출력 = Video
비디오 예측 & 생성(Video Prediction & Generation)
입력 = Text, Prompt 출력 = Video
비디오 검색(Video Retreival)
비디오 추천(Video Recommendation)
Video Captiong은 입력된 Video에 대한 Captions을 생성하는 Task이다. Vision과 Natural Language의 관계를 이해하고 서로 연결할 수 있도록 Feature를 추출하기 위한 Encoder와 문장을 생성하기 위한 Decoder 형태로 이루어져 있다.
SWINBERT: End-to-End Transformers with Sparse Attention for Video Captioning
2022 CVPR에 실린 SWINBERT라는 논문을 통해 이전의 CNN 모델 기반의 연구와 Transformer 기반의 연구들의 Video Captioning 모델들이 어떠한 구조를 가지고 있는지 대략 파악할 수 있었다.
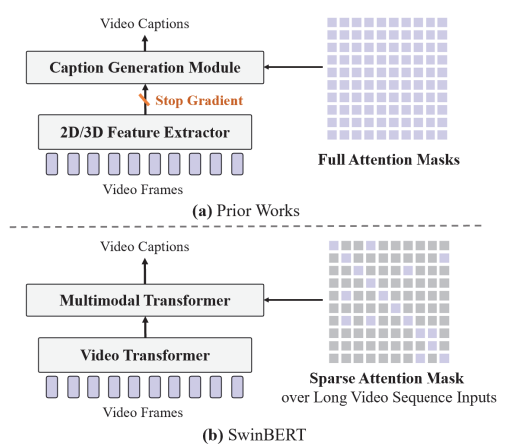
- 기존 연구와의 비교 (Comparison with Previous Works):
- 이전 연구들은 오프라인으로 추출된 2D/3D 특징(offline-extracted 2D/3D features)을 사용했습니다. 이들은 주로 이미지/비디오 이해 작업(image/video understanding tasks)에 대한 훈련을 받았으며, 비디오 캡셔닝 데이터(video captioning data)에 맞게 조정되지 않았습니다. (Stop Gradient)
- Figure 1의 (a) 부분에서는 이러한 방식을 보여줍니다. 다수의 특징 추출기(feature extractors)가 사용되어 비디오 프레임에서 2D 외모 특징(2D appearance features)과 3D 동작 특징(3D motion features)을 추출합니다.
- SWINBERT 접근 방식 (SWINBERT Approach):
- SWINBERT는 비디오 트랜스포머(video transformer)를 비디오 인코더(video encoder)로 채택하고, 완전히 트랜스포머 기반의 모델(fully Transformer-based model)을 제안합니다.
- Figure 1의 (b) 부분에서는 이 새로운 접근 방식을 보여줍니다. SWINBERT는 비디오 프레임 패치(video frame patches)를 직접 입력으로 받아 자연어 설명(natural language description)을 출력합니다.
- 또한, 비디오 시퀀스 모델링(video sequence modeling)에서 더 나은 장기적 성능을 위해, 희소 주의 마스크(sparse attention mask)를 적응적으로 학습하는 것을 제안합니다.
위의 내용을 보면 기존의 연구들은 모델의 구조 상 특징 추출 모델과 캡션 생성 모델이 단절되어 있기 때문에 Stop Gradient가 존재한다. 이는 Backpropagtion을 통해 Video-Caption 데이터에 대한 정보를 학습할 수 없기 때문에 Video Captiong Task에 맞게 조정되지 않음을 알 수 있다. 제안하는 방법은 End-To-End 학습이 가능한 Fully Transformer-based model을 제안하였다. 또한 Sparse Attention Mask를 통해 적응적으로 학습하는 방법을 사용하였다.
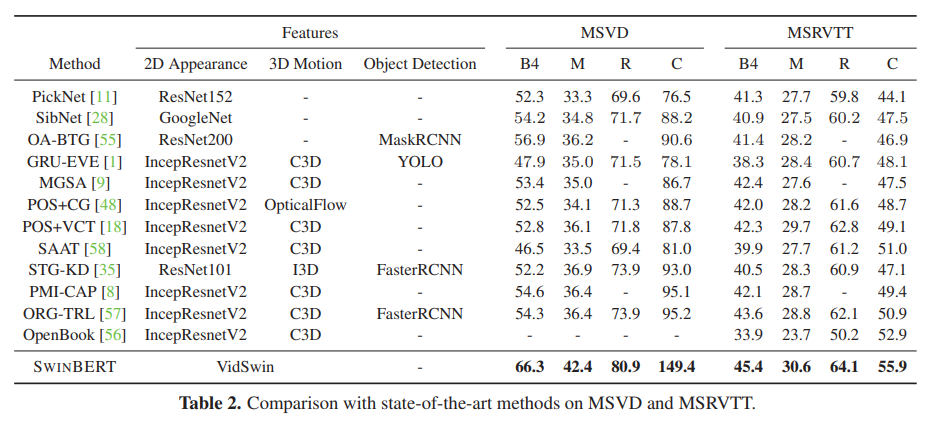
논문의 4.2에 Table 2를 보면 연구의 전체적인 흐름이 보인다. 기존에 SOTA를 기록했던 모델들이 다양한 Feature를 사용하기 위한 모습이 보인다. CNN 기반의 Image feature를 사용하고 대표적으로 ResNet과 IncepResNetV2모델이 사용되어지는 것을 볼 수 있다. Video의 Time Series를 고려한 행동 정보를 추출하기 위한 C3D, Optical Flow 정보를 사용하였다. 추가적으로 Object Detection을 활용하여 객체 정보에 대한 특징을 사용한 다양한 방법들도 볼 수 있다.
저자가 제안하는 방법인 SwinBERT는 VidSwin이라는 완전 트랜스포머 기반의 모델을 사용함으로 기존의 모델들보다 다양한 벤치마크 데이터세트에 대해서 월등히 높은 기록을 보였다.
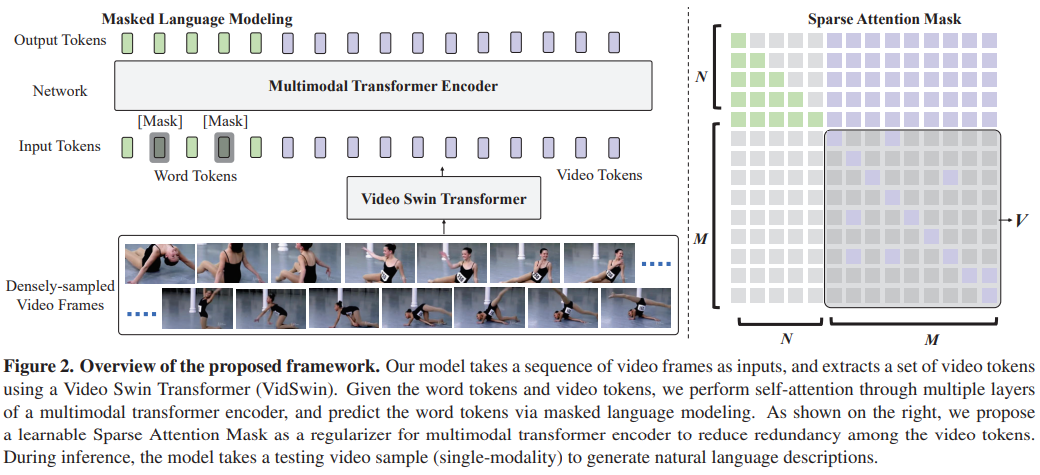
Figure 2는 저자가 제안하는 방법의 프레임워크이다. 모델은 다음과 같은 특징들을 가지고 있다.
- 모델 구조 (Model Structure):
- Figure 2는 비디오 프레임 시퀀스를 입력으로 받고, 비디오 토큰(video tokens) 세트를 추출한 다음, 다중 모달 트랜스포머 인코더(multimodal transformer encoder)를 통해 자기주의(self-attention)를 수행하고, 마스킹된 언어 모델링(masked language modeling)을 통해 단어 토큰(word tokens)을 예측하는 모델의 전체 프로세스를 보여줍니다.
- 비디오 스윈 트랜스포머 (Video Swin Transformer):
- 비디오 프레임에서 공간-시간적 표현(spatial-temporal representations)을 추출하기 위해 사용됩니다. 이 모델은 비디오 토큰을 생성하여 멀티모달 트랜스포머 인코더에 입력으로 제공합니다.
- 멀티모달 트랜스포머 인코더 (Multimodal Transformer Encoder):
- 비디오 토큰과 단어 토큰을 입력으로 받아, 시퀀스-투-시퀀스(sequence-to-sequence) 생성을 통해 자연어 문장을 출력합니다.
- 희소 주의 마스크 (Sparse Attention Mask):
- 이 마스크는 멀티모달 트랜스포머 인코더 내에서 비디오 토큰들 사이의 중복을 줄이기 위한 정규화(regularizer) 역할을 합니다. 이를 통해 모델이 비디오 시퀀스의 중요한 부분에 더 집중할 수 있도록 합니다.
- 마스킹된 언어 모델링 (Masked Language Modeling):
- 훈련 과정에서 일부 단어 토큰을 마스킹하고, 모델이 이를 예측하도록 함으로써, 비디오 콘텍스트에 대한 이해를 강화합니다.
비디오 스윈 트랜스포머 (Video Swin Transformer)
- 특징 추출과 토크나이제이션 (Feature Extraction and Tokenization):
- 비디오 스윈 트랜스포머는 마지막 인코더 블록에서 그리드 형태의 특징을 추출합니다. 이 그리드 특징은 T * H/32 * W/32 * 8C 크기로 정의되며, 여기서 는 채널 차원을 의미합니다.
- 그 후, 채널 차원을 따라 그리드 특징을 토크나이즈하여 총 T * H/32 * W/32 개의 비디오 토큰을 생성합니다. 각 토큰은 8C차원의 특징 벡터입니다.
- 캡션 생성을 위한 멀티모달 트랜스포머 인코더 입력 (Input to Multimodal Transformer Encoder for Caption Generation):
- 생성된 비디오 토큰은 멀티모달 트랜스포머 인코더로 입력되어 자연어 설명을 생성하는 데 사용됩니다.
위 내용을 온전히 이해하기 위해서는 Swin Transformer, VidSwin 두 논문을 보아야 할 것 같다.
Swin Transformer : https://arxiv.org/abs/2103.14030
Swin Transformer: Hierarchical Vision Transformer using Shifted Windows
This paper presents a new vision Transformer, called Swin Transformer, that capably serves as a general-purpose backbone for computer vision. Challenges in adapting Transformer from language to vision arise from differences between the two domains, such as
arxiv.org
VidSwin : https://arxiv.org/abs/2106.13230
Video Swin Transformer
The vision community is witnessing a modeling shift from CNNs to Transformers, where pure Transformer architectures have attained top accuracy on the major video recognition benchmarks. These video models are all built on Transformer layers that globally c
arxiv.org
모델 구조에 대한 대략적인 흐름은 위와 같은 내용이다. 특정 태스크(감시 시스템)를 해결하기 위한 방법으로 Video Captioning 모델을 사용하고자 할 때 모델 구조상 발생할 수 있는 한계점과 문제점을 미리 고려해야 한다.
다음은 특정 Application에 Video Captioning을 적용한 사례들을 알아보고자 한다.
'논문 분석 > Videp captioning' 카테고리의 다른 글
| Dense Video Captioning 관련 논문 (0) | 2023.11.28 |
|---|---|
| Video Captioning 최신 연구 동향 [1] (4) | 2023.11.27 |