Surveillance system에 적용된 Video captioning 연구 사례 & 활용 가능성
Dense Video captioning에 대한 최신 연구(2022-2033)
End-to-End Dense Video Captioning as Sequence Generation: This paper discusses the concept of dense video captioning, which involves identifying events of interest in a video and generating descriptive captions for each event. The process typically follows a two-stage generative approach, starting with proposing a segment for each event and then rendering a caption for each identified segment.
A Latent Topic-Aware Network for Dense Video Captioning - Xu - 2023: This research focuses on the challenging task of locating multiple events from a long, untrimmed video and describing them with sentences or a paragraph. The paper proposes a novel LTNet to enhance the relevance and semantic quality of the predicted captions.
Dense Video Captioning Based on Local Attention - Qian - 2023: This study, first published in May 2023, explores dense video captioning with a focus on local attention. It aims to locate multiple events in an untrimmed video and generate captions for each.
Dense Video Captioning Using BiLSTM Encoder | IEEE Conference: Presented in May 2022, this paper discusses dense video captioning as a newly emerging research subject. It involves presenting temporal events in a video and creating captions for each temporal event.
Dense Video Captioning with Early Linguistic Information Fusion (2023): This paper proposes a Visual-Semantic Embedding (ViSE) Framework that models word-context distributional properties over the semantic space and computes weights for n-grams, assigning higher weights to more informative n-grams.
각 Application 영역에서 Video captioning의 연구 사례 & 활용 가능성
Surveillance system에 적용된 Video captioning 연구 사례 & 활용 가능성
Model 영역
Video captioning의 주요 사용 모델 및 구조
Video Understanding 분야에는 다양한 Task를 포함하고 있다.
입력 = Video 출력 = Text
비디오 분류(Video Classification)
비디오 캡셔닝(Video Captioning)
비디오 질의응답(Video Question & Answering on Video)
입력 = Video 출력 = Video
비디오 예측 & 생성(Video Prediction & Generation)
입력 = Text, Prompt 출력 = Video
비디오 검색(Video Retreival)
비디오 추천(Video Recommendation)
Video Captiong은 입력된 Video에 대한 Captions을 생성하는 Task이다. Vision과 Natural Language의 관계를 이해하고 서로 연결할 수 있도록 Feature를 추출하기 위한 Encoder와 문장을 생성하기 위한 Decoder 형태로 이루어져 있다.
SWINBERT: End-to-End Transformers with Sparse Attention for Video Captioning
2022 CVPR에 실린 SWINBERT라는 논문을 통해 이전의 CNN 모델 기반의 연구와 Transformer 기반의 연구들의 Video Captioning 모델들이 어떠한 구조를 가지고 있는지 대략 파악할 수 있었다.
기존 연구와의 비교 (Comparison with Previous Works):
이전 연구들은 오프라인으로 추출된 2D/3D 특징(offline-extracted 2D/3D features)을 사용했습니다. 이들은 주로 이미지/비디오 이해 작업(image/video understanding tasks)에 대한 훈련을 받았으며, 비디오 캡셔닝 데이터(video captioning data)에 맞게 조정되지 않았습니다. (Stop Gradient)
Figure 1의 (a) 부분에서는 이러한 방식을 보여줍니다. 다수의 특징 추출기(feature extractors)가 사용되어 비디오 프레임에서 2D 외모 특징(2D appearance features)과 3D 동작 특징(3D motion features)을 추출합니다.
SWINBERT 접근 방식 (SWINBERT Approach):
SWINBERT는 비디오 트랜스포머(video transformer)를 비디오 인코더(video encoder)로 채택하고, 완전히 트랜스포머 기반의 모델(fully Transformer-based model)을 제안합니다.
Figure 1의 (b) 부분에서는 이 새로운 접근 방식을 보여줍니다. SWINBERT는 비디오 프레임 패치(video frame patches)를 직접 입력으로 받아 자연어 설명(natural language description)을 출력합니다.
또한, 비디오 시퀀스 모델링(video sequence modeling)에서 더 나은 장기적 성능을 위해, 희소 주의 마스크(sparse attention mask)를 적응적으로 학습하는 것을 제안합니다.
위의 내용을 보면 기존의 연구들은 모델의 구조 상 특징 추출 모델과 캡션 생성 모델이 단절되어 있기 때문에 Stop Gradient가 존재한다. 이는 Backpropagtion을 통해 Video-Caption 데이터에 대한 정보를 학습할 수 없기 때문에 Video Captiong Task에 맞게 조정되지 않음을 알 수 있다. 제안하는 방법은 End-To-End 학습이 가능한 Fully Transformer-based model을 제안하였다. 또한 Sparse Attention Mask를 통해 적응적으로 학습하는 방법을 사용하였다.
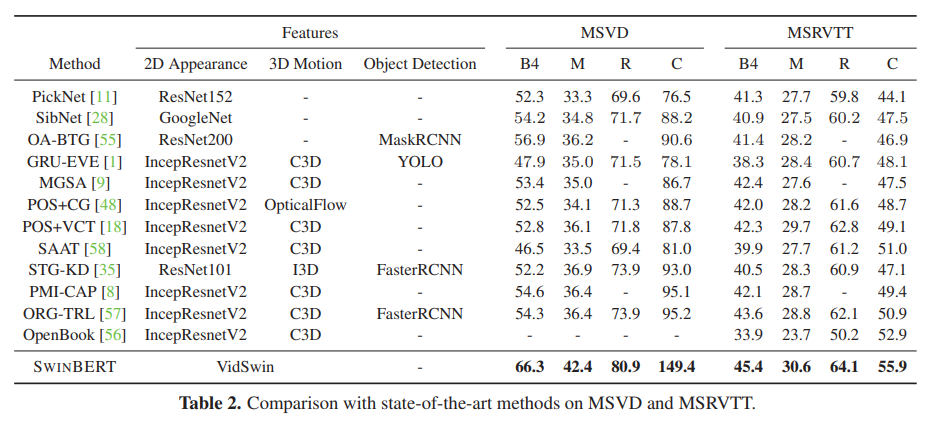
논문의 4.2에 Table 2를 보면 연구의 전체적인 흐름이 보인다. 기존에 SOTA를 기록했던 모델들이 다양한 Feature를 사용하기 위한 모습이 보인다. CNN 기반의 Image feature를 사용하고 대표적으로 ResNet과 IncepResNetV2모델이 사용되어지는 것을 볼 수 있다. Video의 Time Series를 고려한 행동 정보를 추출하기 위한 C3D, Optical Flow 정보를 사용하였다. 추가적으로 Object Detection을 활용하여 객체 정보에 대한 특징을 사용한 다양한 방법들도 볼 수 있다.
저자가 제안하는 방법인 SwinBERT는 VidSwin이라는 완전 트랜스포머 기반의 모델을 사용함으로 기존의 모델들보다 다양한 벤치마크 데이터세트에 대해서 월등히 높은 기록을 보였다.
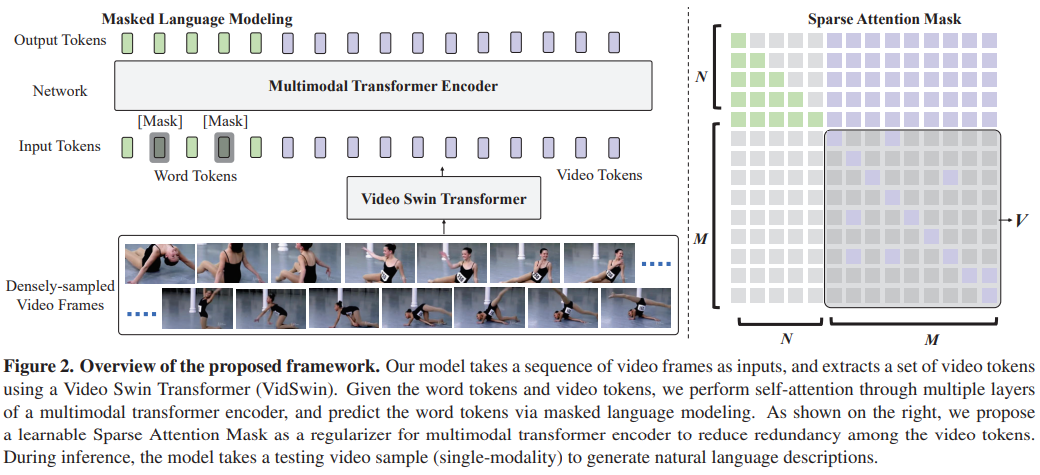
Figure 2는 저자가 제안하는 방법의 프레임워크이다. 모델은 다음과 같은 특징들을 가지고 있다.
모델 구조 (Model Structure):
Figure 2는 비디오 프레임 시퀀스를 입력으로 받고, 비디오 토큰(video tokens) 세트를 추출한 다음, 다중 모달 트랜스포머 인코더(multimodal transformer encoder)를 통해 자기주의(self-attention)를 수행하고, 마스킹된 언어 모델링(masked language modeling)을 통해 단어 토큰(word tokens)을 예측하는 모델의 전체 프로세스를 보여줍니다.
비디오 스윈 트랜스포머 (Video Swin Transformer):
비디오 프레임에서 공간-시간적 표현(spatial-temporal representations)을 추출하기 위해 사용됩니다. 이 모델은 비디오 토큰을 생성하여 멀티모달 트랜스포머 인코더에 입력으로 제공합니다.
멀티모달 트랜스포머 인코더 (Multimodal Transformer Encoder):
비디오 토큰과 단어 토큰을 입력으로 받아, 시퀀스-투-시퀀스(sequence-to-sequence) 생성을 통해 자연어 문장을 출력합니다.
희소 주의 마스크 (Sparse Attention Mask):
이 마스크는 멀티모달 트랜스포머 인코더 내에서 비디오 토큰들 사이의 중복을 줄이기 위한 정규화(regularizer) 역할을 합니다. 이를 통해 모델이 비디오 시퀀스의 중요한 부분에 더 집중할 수 있도록 합니다.
마스킹된 언어 모델링 (Masked Language Modeling):
훈련 과정에서 일부 단어 토큰을 마스킹하고, 모델이 이를 예측하도록 함으로써, 비디오 콘텍스트에 대한 이해를 강화합니다.
비디오 스윈 트랜스포머 (Video Swin Transformer)
특징 추출과 토크나이제이션 (Feature Extraction and Tokenization):
비디오 스윈 트랜스포머는 마지막 인코더 블록에서 그리드 형태의 특징을 추출합니다. 이 그리드 특징은 T * H/32 * W/32 * 8C 크기로 정의되며, 여기서 C는 채널 차원을 의미합니다.
그 후, 채널 차원을 따라 그리드 특징을 토크나이즈하여 총 T * H/32 * W/32개의 비디오 토큰을 생성합니다. 각 토큰은 8C차원의 특징 벡터입니다.
캡션 생성을 위한 멀티모달 트랜스포머 인코더 입력 (Input to Multimodal Transformer Encoder for Caption Generation):
생성된 비디오 토큰은 멀티모달 트랜스포머 인코더로 입력되어 자연어 설명을 생성하는 데 사용됩니다.
위 내용을 온전히 이해하기 위해서는 Swin Transformer, VidSwin 두 논문을 보아야 할 것 같다.
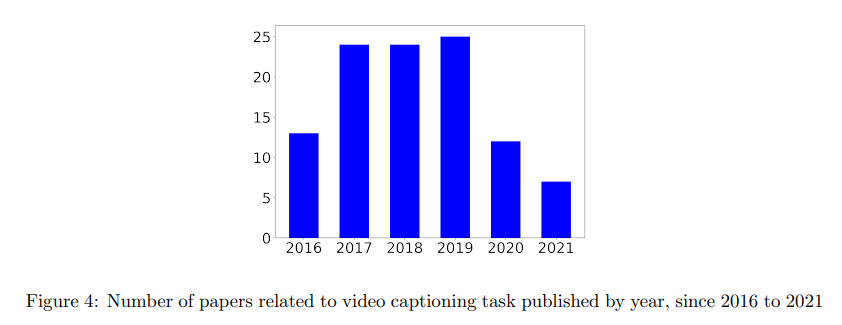
먼저 2016년부터 2021년까지의 Video Captiong을 Review한 논문 "Video Captioning: a comparative review of where we are and which could be the route" (2023-04)를 기반으로 기존 연구들에 대한 Video Captioning 연구의 목적과 방향을 정리한다.
연구 동향
Video captioning의 개요 및 정의
Video captioning의 주요 연구 분야
Video captioning의 최근 연구 동향
Application 영역
각 Application 영역에서 Video captioning의 연구 사례 & 활용 가능성
Surveillance system에 적용된 Video captioning 연구 사례 & 활용 가능성
1. Video captioning의 개요 및 정의
Video Explanation
주어진 영상의 내용을 한 눈에 알아볼 수 있도록 정리/요약/분류해주는 모든 방법들을 의미한다. 주로 사용되는 방식들은 다음과 같다.
Dense Video captioning : 주어진 영상에 대해서 매 프레임마다 Caption을 생성하는 기술
Video Captioning : 주어진 영상을 설명하는 하나의 Caption을 생성하는 기술
Classification : 주어진 영상을 특정 카테고리로 분류하는 기술
Image vs Video
이미지와 비디오 캡션의 차이점은 비디오에서는 이미지 간의 의존성이 존재한다는 것이다. 컨텐츠의 의미를 이해하기 위해 전체 시퀀스(또는 적어도 일부)를 처리하여 이를 설명하는 문장을 생성해야 한다. 어떤 장면을 이해하기 위해서는 일정 시퀀스동안의 정보가 누적되어야만 하는 정보들이 있다. 보통 캡션에 명사로 표현되는 객체, 장소가 아닌 동사, 동명사로 표현되어지는 행동 정보들이 그렇다. 결국 Image 수준에서는 한계를 가지는 이 정보를 올바르게 이해하기 위해서는 Video 수준의 해석이 필수적이다.
VC 연구의 정보 특징 기반 접근 방식
시간적 단서 활용 (Exploiting Temporal Cues):
정의 : 비디오 내 시간적 순서와 관계를 분석하여 중요한 정보를 추출하는 방식입니다.
특징 : 시간적 변화를 감지하여 사건의 발전이나 변화를 이해합니다.
예시 : 비디오에서 인물이 움직이는 경로나 사물의 변화를 추적하여 그 순서대로 사건을 서술하는 경우.
움직임 (Motion):
정의 : 비디오 내의 객체나 인물의 움직임을 감지하고 분석하는 방법입니다.
특징 : 동적인 환경에서의 사물이나 인물의 움직임을 중점적으로 캡처합니다.
예시 : 카메라 앞에서 춤추는 사람의 동작을 분석하여 이를 텍스트로 서술하는 경우.
행동 인식 (Action Recognition):
정의: 비디오 내의 인물이 수행하는 구체적인 행동을 인식하고 분류하는 기술입니다.
특징: 특정 행동의 패턴을 인식하여 무엇을 하고 있는지를 파악합니다.
예시: 운동 경기 비디오에서 선수들의 특정 행동(예: 슛, 패스)을 인식하고 이를 설명하는 경우.
사람 궤적 분석 (People Trajectories):
정의: 비디오에서 사람들의 이동 경로를 추적하고 분석하는 방식입니다.
특징: 개별 인물의 이동 패턴과 경로를 중점적으로 관찰합니다.
예시: 쇼핑몰의 보안 카메라 비디오에서 방문객들의 이동 경로를 분석하는 경우.
이벤트 감지 (Events Detection):
정의: 비디오 내에서 발생하는 특정 사건이나 활동을 감지하는 기술입니다.
특징: 중요한 사건이나 활동을 식별하여 이를 강조합니다.
예시: 도시 교통 모니터링에서 교통 사고와 같은 특정 이벤트를 감지하는 경우.
광학 흐름 (Optical Flow):
정의: 비디오 내 객체나 사람의 움직임을 픽셀 변화로 감지하는 방법입니다.
특징: 시각적인 움직임을 연속적인 이미지 시퀀스로부터 추출합니다.
예시: 차량이나 사람들의 움직임을 비디오에서 연속적인 이미지로 분석하는 경우.
오디오 (Audio):
정의: 비디오의 사운드 트랙을 분석하여 중요한 오디오 정보를 추출하는 방식입니다.
특징: 음성, 음악, 배경 소리 등 오디오 신호를 분석합니다.
예시: 영화에서 대화나 배경 음악을 분석하여 비디오의 내용을 서술하는 경우.
음성 인식 (Speech Recognition):
정의: 비디오 내의 음성 데이터를 텍스트로 변환하는 기술입니다.
특징: 대화나 설명 등의 음성을 인식하여 이를 텍스트로 전환합니다.
예시: 뉴스 방송에서 앵커의 대화를 텍스트로 변환하여 내용을 서술하는 경우.
위와 같은 특징 기반의 접근 방식에 딥러닝 모델의 구조 및 설계, 사용된 데이터셋, 성능 측정 및 평가 방식의 대한 설명을 함께하여 다양한 기존 연구들을 분석하고자 한다.
2. Problem definition (문제 정의)
VC의 주요 목표는 컴퓨터가 영상에서 일어나는 일을 이해하고 그 상황과 해당 자연어로 이루어진 캡션 사이의 견고한 관계를 구축할 수 있도록 하는 것이다. VC는 영상의 내용을 설명하기 위한 일련의 자연어 문장을 생성하는 자동화된 작업으로 볼 수 있다.
VC 작업을 공식화하면 다음과 같다. 데이터 세트 D에서 (xs, ys) 쌍이 주어진 경우, xs는 이미지의 집합 또는 시퀀스 xs1, xs2, ..., xsn이고 ys는 단어의 시퀀스 ys = (w1, w2, ..., wm)으로 xs의 내용을 설명한다. 이 경우 D에 있는 모든 쌍 (xs, ys)에 대해 각 이미지 시퀀스 xs에 해당하는 설명 ys의 가장 높은 확률을 찾는 모델을 의미한다. 일반적인 VC 작업에 대한 구조는 다음과 같다.
적절한 길이의 xs를 찾는 방법은? 큰 특징의 변화? 새로운 객체의 등장?
Video Captioning: a comparative review of where we are and which could be the route
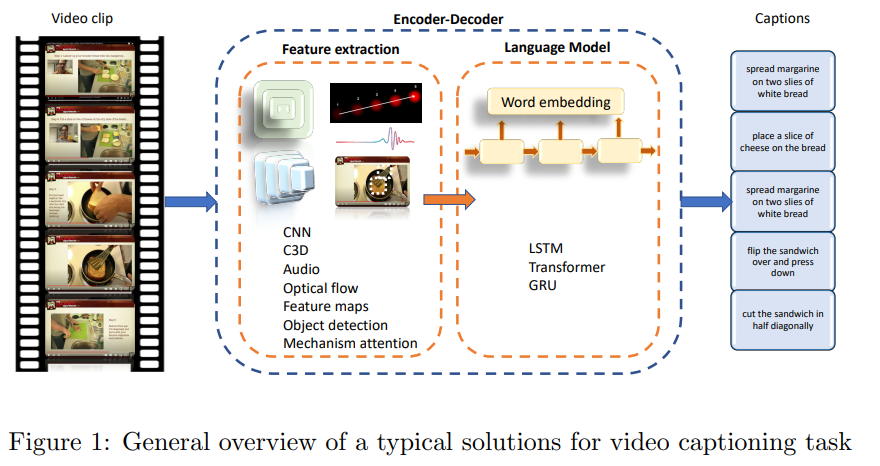
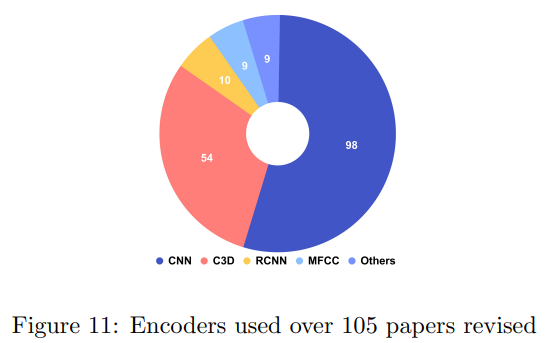
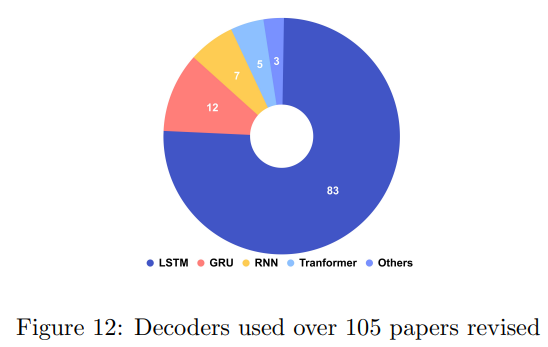
보통 VC를 해결하는 연구들은 인코더-디코더 프레임워크를 사용한다. 인코더는 비디오의 특징을 추출하고, 디코더는 이러한 특징을 사용하여 텍스트 설멸을 생성한다. 위의 그림의 인코더에서 특징을 얻기 위한 다양한 기술이 나타나있다. CNN은 합성곱 신경망으로 ResNet과 같은 모델을 통해 특징을 추출한다. C3D는 3D 합성곱 신경망으로 프레임별로 2차원 Tensor로 변환하여 특징을 추출한 뒤 시간축에 따라 연결하는 방식과 한번에 연결된 시퀀스-이미지 데이터를 사용하여 특징을 추출하는 방식이 있다. 그 외 에도 Audio, Optical flow, Object detection, Attention 등 다양한 특징이 사용되어진다.
사전 처리 (Preprocessing)
주어진 동영상의 각 요소를 컴퓨터 모델이 처리할 수 있도록 바꿔주는 작업(벡터화)이 필요하다. 과거에는 동영상의 각 모달리티마다 특성을 고려한 변환을 진해앟여 임베딩 벡터를 얻었다.
텍스트 → FastText
이미지 →ResNet
현재에는 딥러닝의 발전에 따라, Transformer 구조 기반의 임베딩 추출이 가장 좋은 성능을 보인다.
텍스트 → BERT, RoBERTa
이미지 →ViT, BEiT
텍스트 & 이미지 복합 →LXMERT, VL-BEiT
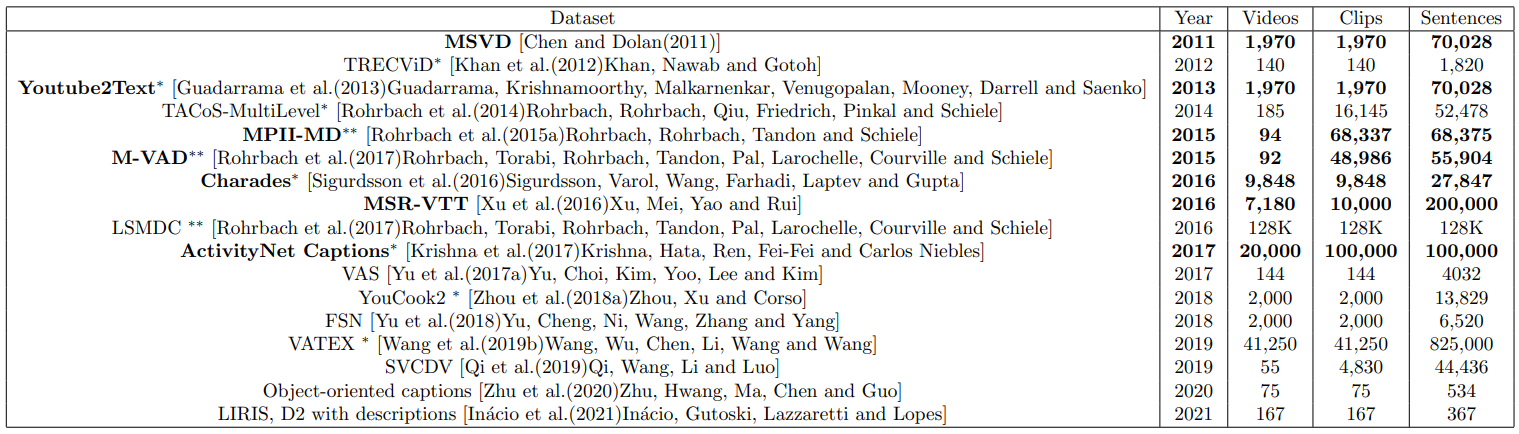
데이터셋 (Datasets)
비디오 캡셔닝에 사용되는 공개 데이터세트들은 주로 요리 또는 영화 클립과 관련이 있다. 특정 태스크에 대한 작업을 하기 위해서는 따로 검색하거나 수집이 필요할 것이다.
MSVD (MS-Video YoutubeClips):
2011년에 제안된 최초의 데이터셋 중 하나로, 1,970개의 클립과 70,028개의 문장(평균 8.7단어)이 포함됨.
전체 비디오 지속 시간은 5.3시간이며, 13,010개의 다른 용어가 있음.
과거에 다운로드 가능했으나 현재는 공식 Microsoft 사이트에서 링크가 비활성화됨.
TRECvideo Data (TRECViD):
뉴스, 회의, 군중, 그룹화, 교통, 음악, 스포츠, 동물, 사람과 객체의 상호작용과 관련된 비디오로 구성됨.
140개의 비디오가 있으며, 각 비디오에는 20개의 세그먼트가 있음.
공식 사이트에서 이용 가능하며, 클립과 주석은 매년 다양한 작업을 위해 업데이트됨.
TACoS-MultiLevel:
TACoS 데이터셋에 기반을 둔 것으로, 다양한 요리에 대한 185개의 비디오와 총 52,478개의 문장을 포함함.
공식 사이트를 통해 다운로드 가능하며, MPII Cooking 2 데이터셋과 연관됨.
Youtube2Text:
MSVD의 하위 집합으로, 주로 영어를 사용하며, 훈련 및 테스트를 위해 인접 비디오에 대한 고유한 분할을 제안함.
MSVD와 달리, 파생된 영어 말뭉치는 웹사이트에서 찾을 수 있음.
MPII-Movie Description corpus (MPII):
영화에 속하는 비디오의 모음으로, 주로 영화의 오디오 설명을 제공하기 위한 목적임.
94개의 비디오, 68,337개의 클립, 68,375개의 문장을 포함하며, 총 지속 시간은 73.6시간임.
Video 데이터에 대해서 Temporal segmentation을 했다는 것은, 비디오 데이터를 시간 순서에 따라 연속적인 프레임으로 구성된 단일 덩어리에서 서로 다른 액션이나 이벤트로 구성된 여러 개의 덩어리로 분할했다는 것을 의미합니다. Temporal segmentation을 통해 비디오 데이터를 서로 다른 덩어리로 분할함으로써, 각 덩어리의 특징을 파악하고, 비디오 데이터에 대한 다양한 분석을 수행할 수 있습니다. Temporal segmentation의 3가지 방식은 다음과 같다.
Motion-based segmentation
Object-based segmentation
Event-based segmentation
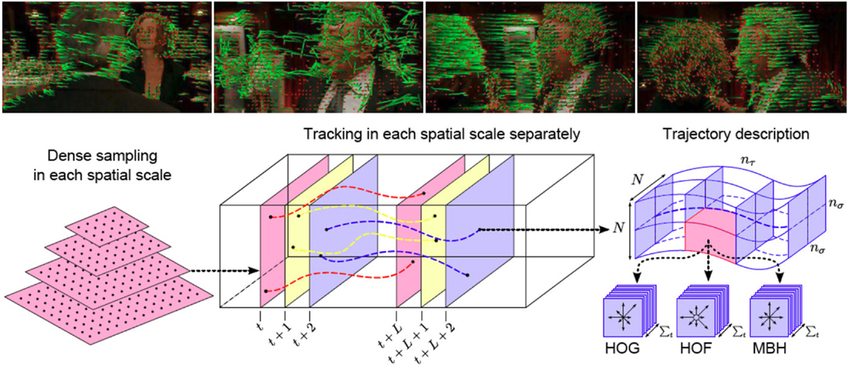
Dense Trajectories 접근법을 사용하여 동작 특징을 추출하고, 시간적 행동 지역화를 위해 시간적 슬라이딩 윈도우와 비최대 억제를 사용합니다.
Dense Trajectories 접근법은 비디오 데이터에서 물체의 움직임을 추적하기 위한 방법입니다. 이 방법은 물체의 각 프레임에서의 위치와 속도를 사용하여 물체의 궤적을 생성합니다. 동작 특징은 물체의 움직임을 나타내는 특성을 말합니다. 동작 특징은 물체의 속도, 가속도, 방향, 기울기, 곡률 등과 같은 속성으로 구성될 수 있습니다.
시간적 슬라이딩 윈도우는 일정한 크기의 윈도우를 시간 순서에 따라 이동시키는 방법입니다.비최대 억제는 신호 처리에서 사용되는 기법으로, 신호에서 최대값을 제외한 다른 값을 억제하는 방법입니다.
따라서, "Dense Trajectories 접근법을 사용하여 동작 특징을 추출하고, 시간적 행동 지역화를 위해 시간적 슬라이딩 윈도우와 비최대 억제를 사용합니다."라는 문장은 다음과 같이 해석할 수 있습니다.
비디오 데이터에서 Dense Trajectories 접근법을 사용하여 물체의 궤적을 생성합니다. 생성된 궤적에서 동작 특징을 추출합니다. 추출된 동작 특징을 기반으로 시간적 슬라이딩 윈도우를 사용하여 시간적 행동 지역화를 수행합니다. 시간적 행동 지역화는 윈도우 내에서 동작 특징이 비최대 억제를 통해 억제되지 않는 영역을 찾는 과정입니다.
구체적인 예를 들어 설명하면, 다음과 같습니다.
축구 경기 비디오 데이터에서 Dense Trajectories 접근법을 사용하여 선수의 궤적을 생성합니다. 생성된 궤적에서 선수의 속도, 가속도, 방향 등을 추출합니다. 추출된 동작 특징을 기반으로 시간적 슬라이딩 윈도우를 사용하여 시간적 행동 지역화를 수행합니다. 시간적 행동 지역화를 통해 골, 패스, 슛 등과 같은 선수의 핵심적인 액션을 찾을 수 있습니다.
이러한 방법은 비디오 데이터에서 동작을 인식하고, 분석하는 데 효과적으로 사용될 수 있습니다.Dense Trajectories의 예시
여러 프레임에서 자막 생성을 위해 역참조 해결을 사용하며, Stanford CoreNLP의 성별 주석자, POS 태거, 표제화 전략 등을 활용합니다.
다양한 크기의 비디오 세그먼트 내용을 탐색하여 행동을 분류하는 대신 지역화하는 것이 특징입니다.
Xiao and Shi(2019)의 연구:
강화된 적응형 주의 모델 (RAAM)을 사용합니다.
CNN과 Bi-LSTM 네트워크를 사용하여 비디오 특징을 생성하고, 각 단어에 대한 주의를 피하려고 합니다.
단어 수준의 교차 엔트로피를 최소화할 뿐만 아니라 문장 수준에서도 정책 그라디언트를 사용한 혼합 손실 훈련을 제안합니다.
세 개의 단방향 LSTM 계층을 사용하여 디코딩 작업을 수행하며, 다음 단어 생성에 대한 시각적 및 맥락 정보의 결합을 특징으로 합니다.
비디오 캡션 작성 분야에서 개선될 수 있는 여러 영역
일반화 부족:
일부 데이터셋에서 낮은 결과를 보여준 것은 제안된 방법들이 이 작업을 다루는 데 있어 일반화 부족을 나타낼 수 있습니다.
특히, 음성 인식과 움직임 단서와 같은 일부 비디오 콘텐츠 특징들이 누락되거나 사용되지 않는 경우가 있습니다.
선행 연구의 활용 부족:
비디오 행동 인식, 동작, 궤적 분석, 객체 및 분류와 관련된 선행 연구들의 활용이 부족합니다.
가장 우수한 연구들은 시간이나 시간적 단서와 관련된 다양한 동작 특징을 활용합니다.
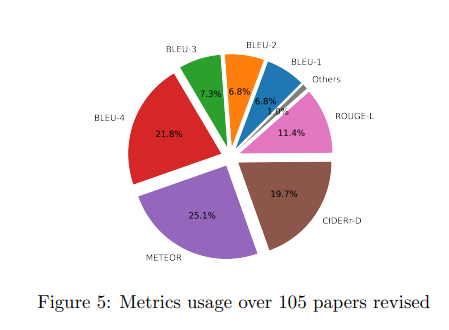
성능 평가 메트릭의 개선:
대부분의 연구는 의미론적 측면과 관련 없는 첫 번째 세대 메트릭(예: BLEU, CIDERr-D)을 사용합니다.
BLEURT, BERTScore, BERTr, CLIPScore와 같은 새로운 메트릭들이 의미론적 또는 문맥적 임베딩을 사용하여 단어의 의미론적 관계를 평가합니다.
실제 적용 분야의 부족:
대부분의 연구들은 공개적으로 이용 가능한 데이터셋에만 그들의 방법을 적용하고 있으며, 실제 시나리오에 적용하는 것은 거의 없습니다.
시각 장애인을 위한 영화 설명이나 레시피 설명과 같은 특정 분야에만 적용됩니다.
스포츠 내레이션과 같은 분야는 거의 탐색되지 않았습니다.
비디오 캡션 작성 작업의 다양한 적용:
스마트 비디오 감시와 같은 다양한 분야에서의 활용 가능성이 있지만, 아직 탐색되지 않았습니다.
실시간으로 중요한 이벤트를 감지하고 캡션을 생성하는 것은 큰 도전입니다.
자동 자막 생성과 시각 장애인을 위한 적용:
실시간 성능과 의미있는 정보 추출의 필요성을 충족시키는 자동 자막 생성이 중요합니다.
모델의 안전성과 강건성을 극대화하여 사용자의 편의성을 높이는 것이 중요합니다.
이러한 개선점들은 비디오 캡션 작성 분야에서의 미래 연구 방향성을 제시하며, 실제 환경에서의 성능 평가 및 적용을 통해 이 분야의 발전에 기여할 수 있을 것입니다.